I am doing an optimization on my PCC model with the goal of exploring the parameter while doing it.
Here is the full PCC process for reference:
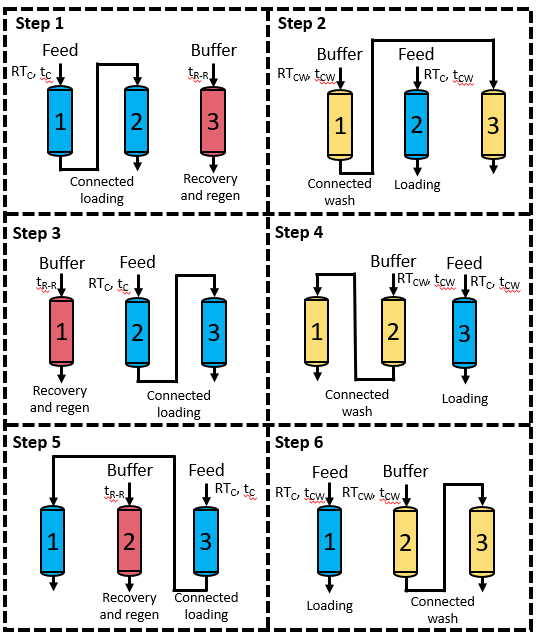
I have noticed something with the stability of the model on the HPC, caviness, the HPC that University of Delaware uses. The model seems to trouble with areas where a small or large amount of protein is loaded.
t_c is the time of loading in the odd steps and RT_c is the residence time of the feed.
t_cw is the time of the even steps and RT_cw is the flowrate of the buffer (not a variable in the optimization yet)
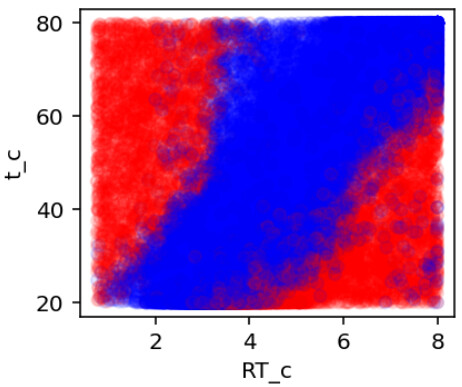
This is the graph for fails and succuss for the optimization. Each circle is a single simulation of the PCC script, where blue means it completed and red means it timed out. The time out for this was around 3 hours. For my local computer this should be enough time for most of those points, however what I have seen is that when CADET is ran on the HPC it takes a lot longer.
Here is a little bit of information about how we run it on the HPC. We are having to limit the amount of threads created so that we can parallelize more.
In the script running CADET we have:
os.environ[“OMP_NUM_THREADS”] = “1”
os.environ[“OPENBLAS_NUM_THREADS”] = “1”
os.environ[“MKL_NUM_THREADS”] = “1”
os.environ[“VECLIB_MAXIMUM_THREADS”] = “1”
os.environ[“NUMEXPR_NUM_THREADS”] = “1”
And in the job script we have:
for envvar in {OMP,OPENBLAS,MKL,NUMEXPR,BLIS}\_NUM_THREADS VECLIB_MAXIMUM_THREADS; do
export ${envvar}=1
echo "${envvar}=${!envvar}"
done
# --- force XDG dirs away from /run/user/$UID ---
export XDG_RUNTIME_DIR="$TMPDIR/xdg_runtime"
export XDG_CACHE_HOME="$TMPDIR/xdg_cache"
export XDG_CONFIG_HOME="$TMPDIR/xdg_config"
export XDG_DATA_HOME="$TMPDIR/xdg_data"
mkdir -p "$XDG_RUNTIME_DIR" "$XDG_CACHE_HOME" "$XDG_CONFIG_HOME" "$XDG_DATA_HOME"
Once again the treads are limited to be safe and the XDG dirs had to be modified so that I would not run into permission issues. For reference if we don’t limit the amount of threads, I can get a single simulation to complete since it completely stalls.
I am wondering if there is something I could do so that more of these simulations could be run?
I have attached the CADET file running it and the data, any entry where performance metrics = 0 is one where it timed out.
Caviness_PCC_Opti_Reduced_1to1_V12_new_tubing_V2_conc_600_Parameter_Population.csv (7.5 MB)
Caviness_PCC_Opti_Reduced_1to1_V12_new_tubing_V2.zip (1.5 MB)