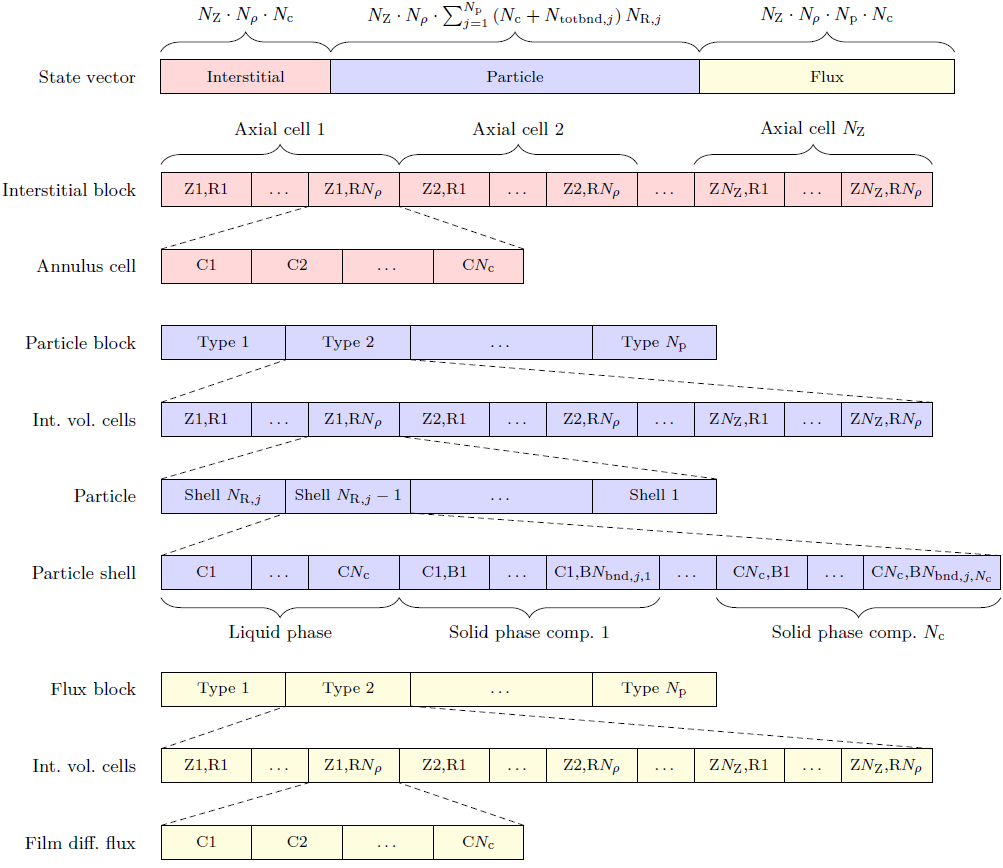
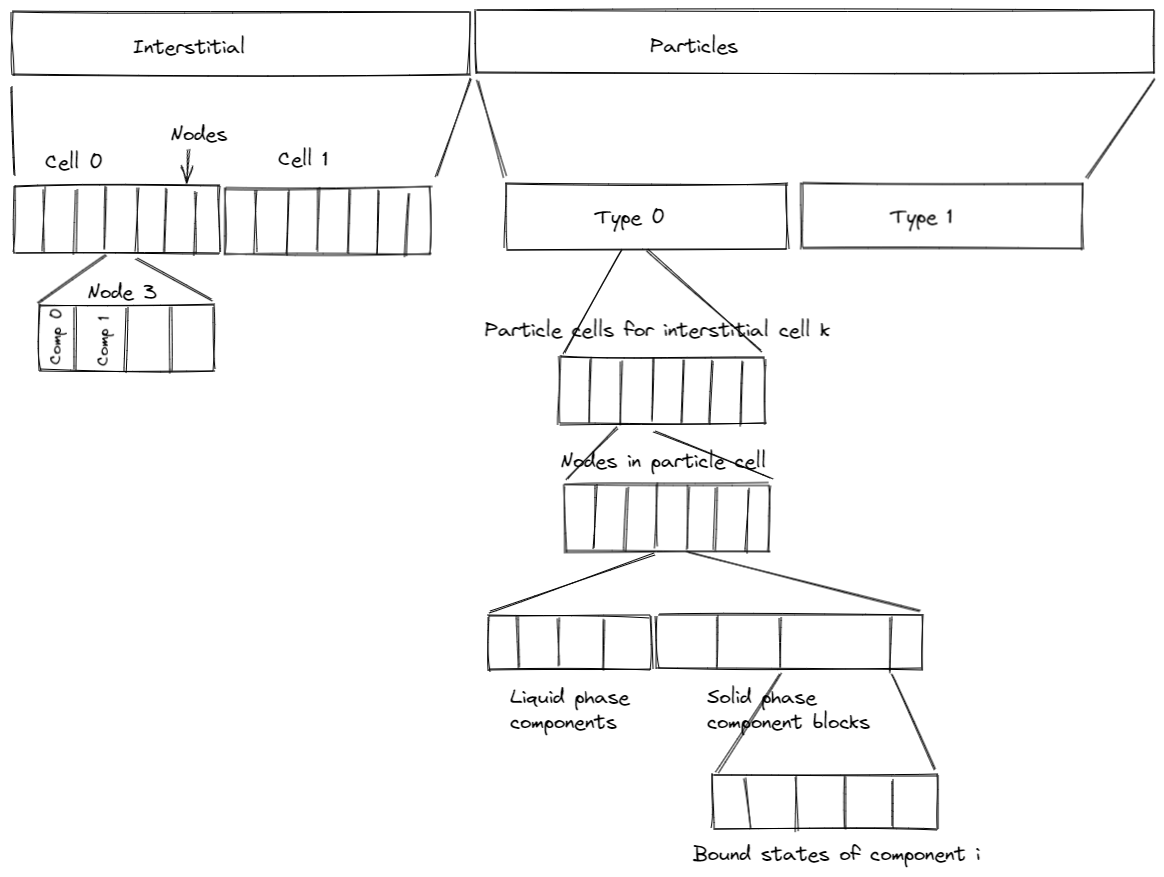
GRM State Ordering (GRM.hpp Line 515-518):
const std::array<StateOrdering, 2> _concentrationOrdering = { { StateOrdering::AxialCell, StateOrdering::Component } };
const std::array<StateOrdering, 4> _particleOrdering = { { StateOrdering::ParticleType, StateOrdering::AxialCell, StateOrdering::ParticleShell, StateOrdering::Component } };
const std::array<StateOrdering, 5> _solidOrdering = { { StateOrdering::ParticleType, StateOrdering::AxialCell, StateOrdering::ParticleShell, StateOrdering::Component, StateOrdering::BoundState } };
const std::array<StateOrdering, 3> _fluxOrdering = { { StateOrdering::ParticleType, StateOrdering::AxialCell, StateOrdering::Component } };
LumpedRateModelwithoutPores State Ordering (Line 356-357):
const std::array<StateOrdering, 2> _concentrationOrdering = { { StateOrdering::AxialCell, StateOrdering::Component } };
const std::array<StateOrdering, 3> _solidOrdering = { { StateOrdering::AxialCell, StateOrdering::Component, StateOrdering::BoundState } };
LumpedRatewithPores State Ordering (Line 443-447):
const std::array<StateOrdering, 2> _concentrationOrdering = { { StateOrdering::AxialCell, StateOrdering::Component } };
const std::array<StateOrdering, 3> _particleOrdering = { { StateOrdering::ParticleType, StateOrdering::AxialCell, StateOrdering::Component } };
const std::array<StateOrdering, 4> _solidOrdering = { { StateOrdering::ParticleType, StateOrdering::AxialCell, StateOrdering::Component, StateOrdering::BoundState } };
const std::array<StateOrdering, 3> _fluxOrdering = { { StateOrdering::ParticleType, StateOrdering::AxialCell, StateOrdering::Component } };
GRM2D State Ordering (Line 500-503):
const std::array<StateOrdering, 3> _concentrationOrdering = { { StateOrdering::AxialCell, StateOrdering::RadialCell, StateOrdering::Component } };
const std::array<StateOrdering, 5> _particleOrdering = { { StateOrdering::ParticleType, StateOrdering::AxialCell, StateOrdering::RadialCell, StateOrdering::ParticleShell, StateOrdering::Component } };
const std::array<StateOrdering, 6> _solidOrdering = { { StateOrdering::ParticleType, StateOrdering::AxialCell, StateOrdering::RadialCell, StateOrdering::ParticleShell, StateOrdering::Component, StateOrdering::BoundState } };
const std::array<StateOrdering, 4> _fluxOrdering = { { StateOrdering::ParticleType, StateOrdering::AxialCell, StateOrdering::RadialCell, StateOrdering::Component } };
CSTR State Ordering (Line 256-257):
const std::array<StateOrdering, 1> _concentrationOrdering = { { StateOrdering::Component } };
const std::array<StateOrdering, 3> _solidOrdering = { { StateOrdering::ParticleType, StateOrdering::Component, StateOrdering::BoundState } };