I have a component system consisting of 6 components. Three of them are accompanying components, the other three are species of my component of interest, ‘IA’. I have experimental data for the sum of these species.
I need to fit the sum of these 3 species to my experimental data. I need to fit to two experiments simultaneously. For example, specifying film diffusion of one species as fitting variable, and finding the one value that produces the least error for both experiment A and B. From what I know, this would require CADET-match. I have read into the CADET-match documentation, and before I start further tests, I would like to ask a question on how to set up my fitting correctly.
So far, when fitting parameters in CADET-process, I adjusted my experimental data by adding columns of zero for every component, except the first species of my component of interest. I implemented my component system as follows:
This means, my excel file of the experimental data has 3 columns of zeros, one column with experimental data for ‘IA’, and then another 2 columns of zeros (and of course, the first column contains the time steps).
Then, I specified ‘IA’ as my component of interest in the comparator, and turned on use_total_concentration_components:
Can you further explain what exactly you are trying to achieve and if possible provide some code examples here? Most of the core functionalities of CADET-Match have been migrated to CADET-Process. Maybe what you are trying to do is achievable CADET-Process after all :).
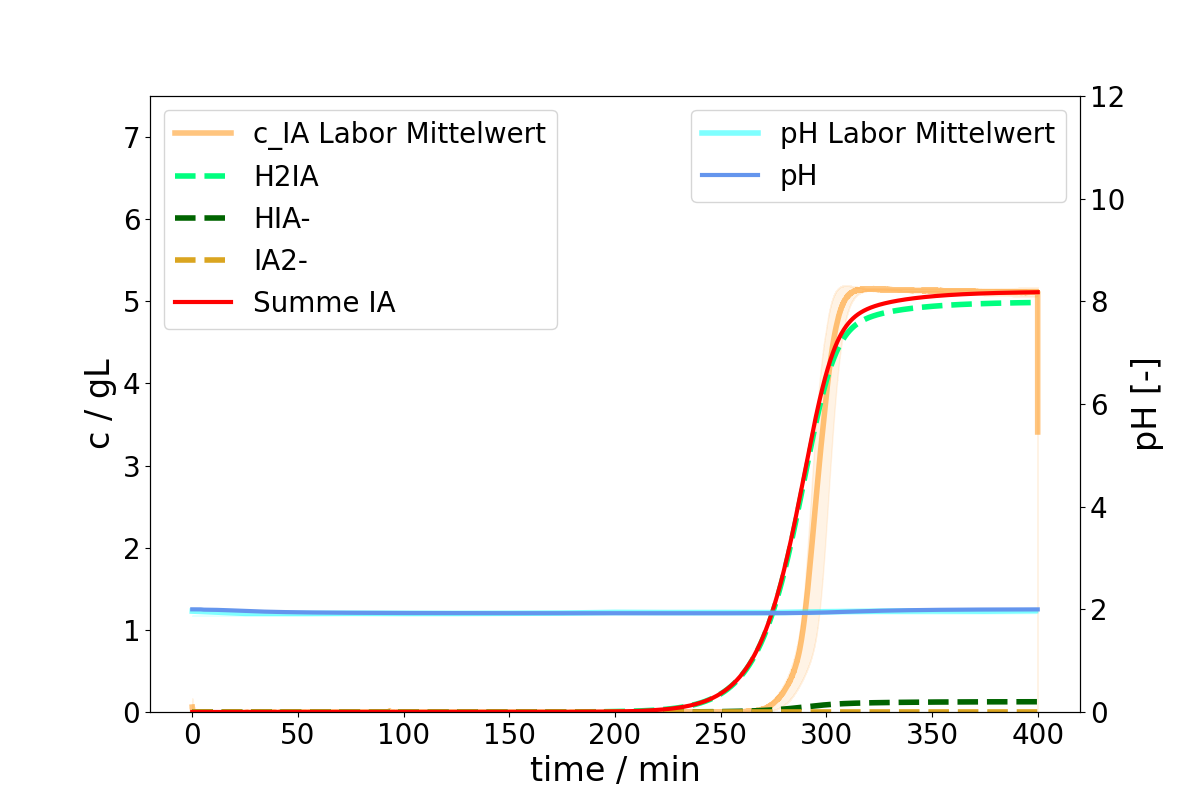
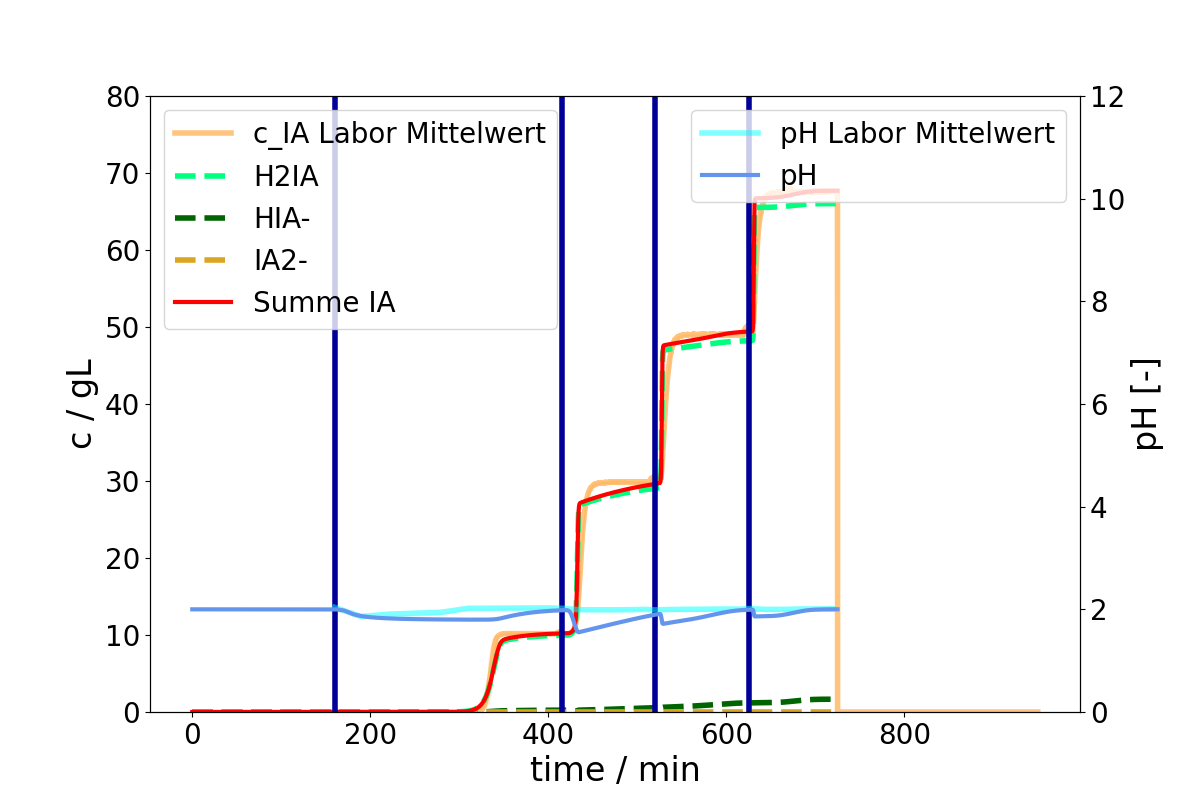
here’s what I’m trying to achieve. I want to align the sum of my three species with my experimental curve. I have two experiments. Experiment A (single step) looks like this:
I want the red curve of the species sum to align better with the orange curve of my experimental data. For simplicity, let’s just say I want to optimize the film diffusion of the species ‘H2IA’.
Up until now, in CADET-Process, I was only able to fit each experiment separately. This means I get 2 results for the film diffusion of the species - one for experiment A, one for experiment B. But I would like to variate the film diffusion in both experiments simultaneously, and find an optimum. Meaning, that I will end up with only one value for the film diffusion - that yields the best result when both experiments were viewed “like one single entity”. Basically, I’m trying to do what this user here did:
But in my case, I have a component system where one component is made up of three species, and I want to fit the sum of the species (=“the component”) to my experimental curve.
I have tried to find out a way to do it in CADET-Process. That sure would be much easier. As far as I’m trying to understand, I would need two references, two processes, and then it all would somehow need to be “unified” in one single difference metric. So that for example I get only one RMSE, which would then be minimized by the optimizer. And this is the step, where I don’t know, if it can possibly be done. Unfortunately, everything fitting-related in CADET is a bit harder to understand for me, and I don’t find every part of it as intuitive as the rest of modeling in CADET.
If it can be done, I would be very glad to receive some hints on how to set up this fitting. This would already solve my problem.
—————————————–
Now, if it can NOT be done in CADET-Process, the question for me would be:
“How do I tell CADET-match to evaluate the difference -of the sum- of my 3 species (in the CADET solution) to my experimental curve?”
I see, I would need to set up a “transform”, for example “auto”, specify a variable path and the index of my component. Here, I have no option like “use_total_concentration_components=True”.
If I specify my component with the three species here, will it automatically use the sum?
In theory, I could install CADET-match and test it all… but I’m in my Bachelor’s thesis currently, and it seemed better to just ask :).
I’m not sure what code examples I could give you to further clarify what I’m trying to do. Code-wise, I have my process model with my LRMP column, and then the implementation of the parameter fitting. I basically just copied that from the “CADET workshop” example, added my own reference and variables, and specified the difference metric arguments like in my initial post. For completeness, I will give you the implementation of my parameter fitting, and an example of my experimental data:
import LaborversucheLoader as LabLoad
fit_components=[3,4,5]
component_names=['H2O','H3O+','OH-','H2IA','HIA-','IA2-']
experimental_data= LabLoad.read_laborversuche(pH, Versuchstyp, current_system)
#Reference
#Reference muss in mM umgerechnet werden
from CADETProcess.reference import ReferenceIO
experimental_data_average = experimental_data[0].sum(1)/3 #c-Mittelwert bilden
experimental_solution= np.zeros([len(experimental_data_average.index),6]) #Leere Lösung experimentelle Daten in der richtigen Shape erzeugen
experimental_solution[:,3]=ER.gL_to_mM(experimental_data_average) # in mM umrechnen und in H2IA-Spalte einfügen
reference = ReferenceIO('experimental data',experimental_data[0].index*60,experimental_solution,component_system=component_system)
from CADETProcess.comparison import Comparator
comparator = Comparator()
comparator.add_reference(reference)
#Difference metrics
comparator.add_difference_metric('RMSE', reference, 'column.outlet',components='IA',use_total_concentration_components=True)
comparator.plot_comparison(simulation_results)
metrics = comparator.evaluate(simulation_results)
from CADETProcess.optimization import OptimizationProblem
optimization_problem = OptimizationProblem('film_diffusion')
optimization_problem.add_evaluation_object(process)
#Optimization Problem
###Variablen###
for comp in fit_components:
optimization_problem.add_variable(
name='film_diffusion_'+component_names[comp],
parameter_path='flow_sheet.column.film_diffusion',
lb=1e-9, ub=1e-3,
transform='auto',
indices=[comp]
)
#Evaluator und Objectives
optimization_problem.add_evaluator(process_simulator)
optimization_problem.add_objective(
comparator,
n_objectives=comparator.n_metrics,
requires=[process_simulator]
)
#Optimizer-Einstellungen
from CADETProcess.optimization import U_NSGA3
optimizer = U_NSGA3()
optimizer.n_cores = 4
optimizer.pop_size = 32
optimizer.n_max_gen = 8
optimization_results = optimizer.optimize(
optimization_problem,
use_checkpoint=False
)
print(optimization_results.x)
print(optimization_results.f)
optimization_results.plot_convergence('objectives')
optimization_results.plot_objectives(autoscale=False)
Explanation: The function “LaborversucheLoader” selects the correct file for my experimental data, and reads it into my variable “experimental data”. experimental_data[0] adressses the excel file of which I share one example with you:
Next, the average of three individual experiments is calculated and converted from g/L to mM. And then, the matrix is created, where every column is zero, except that of the first species. This way, it serves as experimental data for the sum of the species (=the “mother” component).
I add the fitting variables in a for-loop, because specifying a list for “indices”, when trying to fit multiple components simultaneously, did not work. I add variables for indices 3,4,5, which means fitting all three species simultaneously.
The above code does not contain any attempts at mulitple-experiment-fitting.
I hope it is a little bit clearer now. If not, please let me know.
quick side note: everyone here in the forum provides CADET support as volunteers. This is why we ask for precise descriptions and runnable minimal examples. It helps us to quickly assist CADET users while we juggle our own projects.
That said, I think what you are trying to achieve is definitely possible in CADET Process, and since CADET Match is not actively maintained anymore, we would recommend you implement your problem in Process. However, it might be necessary to have some processing steps in between.
From what I understood now, you have two separate tasks:
1) Combine three species into one total and compare to your experimental total
2) Fit the same film diffusion across two processes, using the Comparator as the objective
Regarding combining several experimental results and references into one difference metric, the optimization and difference metric tools can be used independently of the Process object. You can put one or several experiments into the Comparator as metrics, or provide your own objective. The optimizer only sees what you hand over. For reference, this post discusses a similar setup:
There are other valid routes too. For example, keep two objectives and collapse them with a multi criteria decision function inside the optimizer, or use a small custom objective that returns a weighted sum of the two metrics.
Hope that already helps!
Don’t hesitate to ask further questions and also keep in mind our Office Hours.